TL;DR:
- Predictive maintenance relies on high-quality, synchronized data to accurately forecast equipment failures and reduce downtime.
- Effective data governance and ongoing audits are essential to ensure reliability and maximize return on investment.
Predictive maintenance is defined as a condition-based strategy that uses real-time and historical data to anticipate equipment failures before they occur, replacing guesswork with evidence. The role of data in predictive maintenance is to supply the continuous signal stream that makes accurate failure forecasting possible. Organisations using predictive maintenance analytics see 35–50% reductions in unplanned downtime and 25–35% maintenance cost savings, with asset operational life extended by 20–40%. That is not a marginal gain. It is a structural shift in how operations managers protect capital assets, and it begins entirely with data. Platforms such as Microsoft Dynamics 365 Supply Chain Management and Microsoft Fabric demonstrate how integrated data environments translate raw sensor output into maintenance intelligence at scale.

How data quality and governance shape predictive maintenance outcomes
Data quality is the single most decisive factor in whether a predictive maintenance programme delivers results. 60–70% of predictive maintenance initiatives fail to hit ROI targets not because the models are wrong, but because the underlying data is unreliable. That figure should reframe where operations managers invest their attention first.
The most common data problems encountered in practice fall into three categories:
- Inconsistent timestamps. Historian and ERP/CMMS timestamps often differ by minutes, making it impossible to align sensor readings with maintenance events. A time-aligned signal store is not optional. It is the foundation for any meaningful query across data streams.
- Poor maintenance record auditing. Maintenance records are not audited in many organisations, and misdiagnoses appear in one of every four failure labels. When supervised models train on mislabelled failure data, they learn incorrect signals and produce unreliable predictions. The model is only as trustworthy as the records it learns from.
- Absent failure-mode taxonomies. Without a consistent vocabulary for classifying failures, CMMS data becomes fragmented and incomparable across assets, sites, or time periods.
Beyond these technical issues, the gap between operational technology (OT) and information technology (IT) teams creates persistent data governance failures. Sensor data lives in the OT domain. Maintenance records and work orders live in the IT domain. Without data contracts between OT and IT teams that define schema, frequency, and validation rules, model performance degrades silently as data pipelines drift.
Pro Tip: Audit your CMMS records and historian synchronisation at least quarterly. Correct timestamp misalignments and re-label ambiguous failure events before retraining any predictive model. Clean data produces faster, more reliable ROI than any algorithm upgrade.
What types of data are most valuable for predictive maintenance?
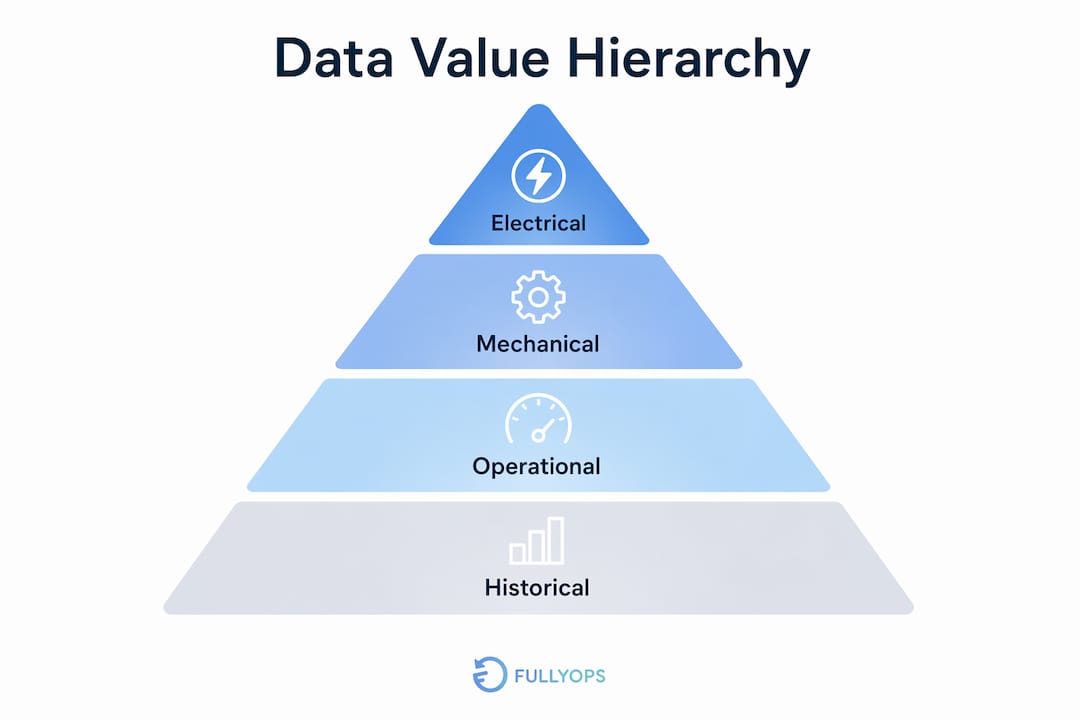
Not all data contributes equally to failure prediction. Understanding which sources carry the most diagnostic weight helps operations managers prioritise sensor investment and avoid collecting data that adds noise without adding insight.
| Data type | Examples | Predictive value | Common failure modes detected |
|---|---|---|---|
| Mechanical | Vibration, acoustic emission | High | Bearing wear, imbalance, misalignment |
| Thermal | Infrared temperature, coolant temp | High | Overheating, insulation breakdown |
| Electrical | Current, voltage waveform, harmonics | Very high | Motor faults, supply issues, winding degradation |
| Operational context | Load state, production rate, cycle count | Medium | False alerts from normal operating variation |
| Process states | Pressure, flow, fluid quality | Medium to high | Pump cavitation, valve wear, contamination |
The category most systematically underrated in maintenance diagnostics is electrical supply data. Electrical supply data such as frequency, phase balance, and harmonics is routinely overlooked, yet monitoring these parameters frequently resolves failures at the supply level, avoiding unnecessary equipment replacements. Motor current signature analysis is particularly powerful because it enables simultaneous diagnosis of mechanical, electrical, and operational issues from a single measurement point. That efficiency makes it one of the highest-value data sources available to maintenance teams.
Operational context data deserves equal attention, though for a different reason. Without knowing whether a machine was running at full load or in standby mode, a temperature spike looks like a fault when it may be entirely normal. Context data prevents false alerts, which erode technician trust in the system and reduce the practical value of any predictive programme.
Pro Tip: If you are starting with limited sensor infrastructure, prioritise machine-level electrical monitoring. Current and voltage waveform data from a single point can surface mechanical, electrical, and supply-related faults simultaneously, giving you the broadest diagnostic coverage per sensor installed.
How analytics techniques use data to improve maintenance decisions
The role of analytics in maintenance is to convert raw data streams into ranked, time-bound predictions that operations teams can act on. The most widely used output is Remaining Useful Life (RUL) prediction, which estimates how long an asset can continue operating before a defined failure threshold is reached. RUL models require synchronised multi-modal data streams including vibration, current, thermal readings, and process states. Without temporal alignment across these streams, even sophisticated deep learning models produce unreliable outputs.
Several analytic approaches are worth understanding in practical terms:
- Supervised machine learning trains on labelled historical failure data to classify current asset states. Its accuracy depends entirely on the quality and completeness of past maintenance records.
- Clustering and unsupervised methods group assets by degradation state without requiring labelled failures. This is particularly useful when failure history is sparse or inconsistently recorded.
- Deep learning models such as convolutional neural networks and recurrent neural networks extract complex temporal patterns from high-frequency sensor data. However, deep learning alone does not remove the need for signal governance. Model sophistication cannot compensate for poor data quality upstream.
- Generative Adversarial Networks (GANs) address a common practical constraint: real failure events are rare, so training datasets are small. GANs generate synthetic failure data to augment training sets, improving model performance without waiting years for additional failure events.
One of the most operationally significant advances in predictive analytics in maintenance is opportunistic maintenance, which clusters components with similar degradation states for joint servicing. Rather than scheduling each asset individually, this approach groups assets approaching similar failure thresholds and services them together, reducing labour costs and production interruptions. True maintenance efficiency moves beyond isolated predictions to coordinated, risk-aware scheduling that accounts for production windows, spare parts availability, and technician capacity.
Monitoring data lifecycle and implementing MLOps practices are what separate pilots that succeed from those that stall after six months. A predictive maintenance programme is not a one-time model deployment. It is an ongoing architecture requiring data governance, model retraining schedules, and performance monitoring.
Pro Tip: Treat your predictive maintenance programme as a product with a lifecycle, not a project with a deadline. Assign ownership of data pipelines and model performance metrics to named individuals, and schedule quarterly reviews of alert accuracy against actual failure outcomes.
Practical strategies for operations managers to harness data effectively
Translating data quality principles into daily operational practice requires a structured approach. The following steps reflect what consistently separates successful data-driven maintenance strategies from those that stall at the pilot stage.
- Audit maintenance records before building any model. Review the last 12 to 24 months of CMMS data. Identify inconsistent failure classifications, missing timestamps, and assets with no recorded failure history. A dataset combining long operational hours with labelled failure events is far more powerful than a large but unlabelled dataset.
- Establish data contracts between OT and IT teams. Define the schema, update frequency, and validation rules for every data source feeding the predictive model. Review these contracts when sensor firmware updates, production processes change, or new assets are commissioned.
- Centralise data in an integrated platform. Platforms such as Microsoft Fabric enable end-to-end asset management and analytics by unifying historian data, CMMS records, and ERP outputs in a single queryable environment. This removes the manual reconciliation that consumes analyst time and introduces errors.
- Build cross-disciplinary ownership. Operations, maintenance, and data teams each hold part of the picture. Maintenance technicians understand failure modes. Data engineers understand pipeline integrity. Operations managers understand production constraints. Decisions made without all three perspectives produce models that are technically correct but operationally impractical.
- Measure data quality as a KPI. Track timestamp alignment rates, label completeness, and sensor uptime alongside traditional maintenance KPIs such as mean time between failures (MTBF) and mean time to repair (MTTR). Teams that treat data quality as a measurable output see 45% decreases in unexpected failures compared to those that do not.
For operations managers exploring how these principles apply to specific asset classes, the Fullyops guide on predictive maintenance reliability provides practical context on reducing downtime through structured data strategies.
Pro Tip: Prioritise data quality over data volume. A clean dataset covering 18 months of one asset class will outperform a poorly labelled dataset covering five years across an entire facility. Start narrow, validate thoroughly, then scale.
Key takeaways
Data quality, not model sophistication, determines whether predictive maintenance delivers measurable ROI, and operations managers who treat data governance as a maintenance asset in its own right consistently outperform those who do not.
| Point | Details |
|---|---|
| Data quality drives ROI | 60–70% of predictive maintenance failures trace to poor data, not flawed models. |
| Electrical data is underrated | Current and voltage waveform monitoring diagnoses mechanical, electrical, and supply faults from one sensor point. |
| Timestamp alignment is non-negotiable | CMMS and historian timestamps must be synchronised to build reliable multi-modal data streams. |
| Opportunistic maintenance reduces costs | Clustering assets by degradation state for joint servicing cuts labour and production interruptions. |
| MLOps sustains performance | Predictive maintenance requires ongoing data governance and model retraining, not a single deployment. |
Why data governance is the maintenance skill most teams underestimate
Having worked closely with operations and maintenance teams across industrial environments, the pattern I see most consistently is this: organisations invest heavily in sensor hardware and analytics platforms, then underestimate the unglamorous work of governing the data those systems produce.
The instinct is understandable. Sensors and software are visible, purchasable, and easy to present in a business case. Data governance feels abstract until a predictive model starts generating alerts that technicians no longer trust. At that point, the investment in hardware and software is effectively stranded.
What I have found is that the teams achieving the best outcomes treat data as a maintenance asset in its own right. They schedule data audits the same way they schedule equipment inspections. They assign data stewardship responsibilities to named individuals, not to “the IT team” as a collective. And they accept that building a reliable data foundation is an incremental process. You do not need perfect data to start. You need good enough data to generate a trustworthy first prediction, then you improve from there.
The cross-disciplinary collaboration point is also worth emphasising. The most technically sophisticated model I have seen fail in practice did so because the maintenance technicians who were supposed to act on its alerts had never been involved in defining what a failure actually looked like. Their institutional knowledge was never captured in the training data. Closing that gap is not a data science problem. It is a people and process problem, and it is entirely solvable with the right organisational commitment.
— Pedro
How Fullyops supports data-driven predictive maintenance
Fullyops is built for operations managers who need more than a work order system. The platform integrates asset management and analytics in a single environment, giving maintenance teams real-time visibility into asset status, intervention history, and performance trends. For teams working to improve their data foundation, Fullyops provides structured resource allocation guidance that aligns maintenance scheduling with asset condition data. Whether you are building your first predictive maintenance programme or scaling an existing one, Fullyops offers the operational infrastructure to connect data quality improvements directly to maintenance outcomes. Visit fullyops.com to explore how the platform supports your asset reliability goals.
FAQ
What is the role of data in predictive maintenance?
Data provides the real-time and historical signal streams that predictive maintenance models use to forecast equipment failures before they occur. Without quality data from sensors, CMMS records, and operational systems, accurate failure prediction is not possible.
Why do most predictive maintenance programmes fail to deliver ROI?
60–70% of predictive maintenance initiatives miss ROI targets due to poor data quality rather than model inaccuracy. The most common causes are inconsistent failure labels, misaligned timestamps between historians and CMMS systems, and absent data governance contracts between OT and IT teams.
Which data sources are most valuable for predictive maintenance?
Electrical supply data, including current waveform, voltage, phase balance, and harmonics, is among the most valuable and most underused. Vibration, thermal, and operational context data are also critical, particularly when synchronised into a unified time-aligned data store.
How does opportunistic maintenance use data to reduce costs?
Opportunistic maintenance uses degradation state data to cluster assets approaching similar failure thresholds and service them together. This reduces the number of production interruptions and lowers labour costs compared to scheduling each asset individually.
How often should maintenance data be audited?
Maintenance records and historian synchronisation should be audited at least quarterly. Label accuracy, timestamp alignment, and sensor uptime should be tracked as formal KPIs alongside MTBF and MTTR to sustain predictive model performance over time.
Recommended
- Predictive maintenance: boost reliability and cut downtime
- Why use predictive maintenance in industrial operations
- Role of analytics in maintenance: a practical guide